My conversation with my former student exactly mirrored discussions I have had with other scientists in pharma and biotech in this regard: a high proportion of the output from academic labs can't be reproduced and is thus worse than useless. "Worse" because it sends companies down dead-end avenues, wasting money and scientific talent that otherwise could be pursuing potential disease therapies with a chance of working. An article in the Wall Street Journal, quoting Bruce Alberts (a prominent scientist and former editor of a prestigious research journal), puts it this way:
Two years ago, a group of Boston researchers published a study describing how they had destroyed cancer tumors by targeting a protein called STK33. Scientists at biotechnology firm Amgen Inc. quickly pounced on the idea and assigned two dozen researchers to try to repeat the experiment with a goal of turning the findings into a drug.
It proved to be a waste of time and money. After six months of intensive lab work, Amgen found it couldn't replicate the results and scrapped the project.
I was disappointed but not surprised," says Glenn Begley, vice president of research at Amgen of Thousand Oaks, Calif. "More often than not, we are unable to reproduce findings" published by researchers in journals.
This is one of medicine's dirty secrets: Most results, including those that appear in top-flight peer-reviewed journals, can't be reproduced. "It's a very serious and disturbing issue because it obviously misleads people" who implicitly trust findings published in a respected peer-reviewed journal, says Bruce Alberts, editor of Science. . . .
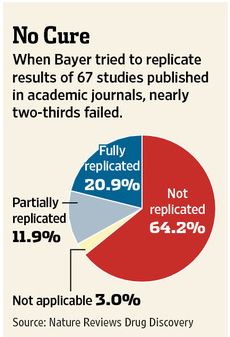
Drug manufacturers rely heavily on early-stage academic research and can waste millions of dollars on products if the original results are later shown to be unreliable. Patients may enroll in clinical trials based on conflicting data, and sometimes see no benefits or suffer harmful side effects.The WSJ article cites a study by the pharmaceutical company Bayer that found that company scientists had to halt 64% of early drug projects based claims in the literature due to inability to replicate published results:
A lot has been written about scientific fraud and how (unsurprisingly) it is probably more prevalent in the highest-prestige journals, about how the scientific literature is biased towards positive results and about the pressures of "publish or perish." I don't have anything new to say about these pressures on academic scientists: pressures that underlie the problem of there being so much garbage in the literature. I will only say this: the "soft money" system that makes scientists' livelihood dependent on winning grants plus the current brutal funding environment is a perfect formula for ensuring increased levels of scientific cheating and the resulting waste and damage to efforts to cure diseases.
This statistic really makes me curious. I mean, although I'm sure some fraud exists, I doubt it is as high as 64% of scientists. Do you have any ideas about this?
ReplyDeleteI've tried to think of a couple of answers for myself. Maybe it reflects the small sample sizes used (at least in animal work) in academia leading to false positives? Or grad students performing new techniques that they don't fully understand? But I am just speculating.
Thanks for your comment. I agree that 64% seems too high to be accounted for by outright fraud, and I think your ideas as to why this happens are good ones. Also I think that biomedical scientists--given the various pressures (such as pressure from PIs on postdocs) may be too ready to disregard what they consider outlier data or outlier results or not attempt to spend the time and money to ensure that "good" results can be reproduced.
DeleteI am going to quote from a News Blog from the journal Nature below. First I want to provide the link because it also addresses this issue; interersted readers may want to skip my extended outake and go right to the article:
http://blogs.nature.com/news/2011/09/reliability_of_new_drug_target.html
"An unspoken industry rule alleges that at least 50% of published studies from academic laboratories cannot be repeated in an industrial setting, wrote venture capitalist Bruce Booth in a recent blog post. A first-of-its-kind analysis of Bayer’s internal efforts to validate ‘new drug target’ claims now not only supports this view but suggests that 50% may be an underestimate; the company’s in-house experimental data do not match literature claims in 65% of target-validation projects, leading to project discontinuation.
“ 'People take for granted what they see published,' says John Ioannidis, an expert on data reproducibility at Stanford University School of Medicine in Palo Alto, California. 'But this and other studies are raising deep questions about whether we can really believe the literature, or whether we have to go back and do everything on our own.'
For the non-peer-reviewed analysis, Khusru Asadullah, Head of Target Discovery at Bayer, and his colleagues looked back at 67 target-validation projects, covering the majority of Bayer’s work in oncology, women’s health and cardiovascular medicine over the past 4 years. Of these, results from internal experiments matched up with the published findings in only 14 projects, but were highly inconsistent in 43 (in a further 10 projects, claims were rated as mostly reproducible, partially reproducible or not applicable; see article online here). 'We came up with some shocking examples of discrepancies between published data and our own data,' says Asadullah. These included inabilities to reproduce: over-expression of certain genes in specific tumour types; and decreased cell proliferation via functional inhibition of a target using RNA interference.
Irreproducibility was high both when Bayer scientists applied the same experimental procedures as the original researchers and when they adapted their approaches to internal needs (for example, by using different cell lines). High-impact journals did not seem to publish more robust claims, and, surprisingly, the confirmation of any given finding by another academic group did not improve data reliability. 'We didn’t see that a target is more likely to be validated if it was reported in ten publications or in two publications,' says Asadullah.
Although the analysis is limited by a small sample size, and cannot itself be checked because of company confidentiality concerns, other studies point to similarly sobering conclusions. In one study researchers tried, and largely failed, to repeat the findings of published microarray gene expression analyses by working directly from the data sets the original conclusions were drawn from (Nature Genet. 41, 149–155; 2009). In another study, when an identical sample of proteins was sent to different proteomics laboratories, the vast majority failed to independently, and therefore reproducibly, identify all of the component proteins (Nature Methods 6, 423–430; 2009)."
Thanks for your comment. I agree that 64% seems too high to be accounted for by outright fraud, and I think your ideas as to why this happens are good ones. Also I think that biomedical scientists--given the various pressures (such as pressure from PIs on postdocs) may be too ready to disregard what they consider outlier data or outlier results or not attempt to spend the time and money to ensure that "good" results can be reproduced.
ReplyDeleteI am going to quote from a News Blog from the journal Nature below. First I want to provide the link because it also addresses this issue; interersted readers may want to skip my extended outake and go right to the article:
http://blogs.nature.com/news/2011/09/reliability_of_new_drug_target.html
"An unspoken industry rule alleges that at least 50% of published studies from academic laboratories cannot be repeated in an industrial setting, wrote venture capitalist Bruce Booth in a recent blog post. A first-of-its-kind analysis of Bayer’s internal efforts to validate ‘new drug target’ claims now not only supports this view but suggests that 50% may be an underestimate; the company’s in-house experimental data do not match literature claims in 65% of target-validation projects, leading to project discontinuation.
“ 'People take for granted what they see published,' says John Ioannidis, an expert on data reproducibility at Stanford University School of Medicine in Palo Alto, California. 'But this and other studies are raising deep questions about whether we can really believe the literature, or whether we have to go back and do everything on our own.'
For the non-peer-reviewed analysis, Khusru Asadullah, Head of Target Discovery at Bayer, and his colleagues looked back at 67 target-validation projects, covering the majority of Bayer’s work in oncology, women’s health and cardiovascular medicine over the past 4 years. Of these, results from internal experiments matched up with the published findings in only 14 projects, but were highly inconsistent in 43 (in a further 10 projects, claims were rated as mostly reproducible, partially reproducible or not applicable; see article online here). 'We came up with some shocking examples of discrepancies between published data and our own data,' says Asadullah. These included inabilities to reproduce: over-expression of certain genes in specific tumour types; and decreased cell proliferation via functional inhibition of a target using RNA interference.
Irreproducibility was high both when Bayer scientists applied the same experimental procedures as the original researchers and when they adapted their approaches to internal needs (for example, by using different cell lines). High-impact journals did not seem to publish more robust claims, and, surprisingly, the confirmation of any given finding by another academic group did not improve data reliability. 'We didn’t see that a target is more likely to be validated if it was reported in ten publications or in two publications,' says Asadullah.
Although the analysis is limited by a small sample size, and cannot itself be checked because of company confidentiality concerns, other studies point to similarly sobering conclusions. In one study researchers tried, and largely failed, to repeat the findings of published microarray gene expression analyses by working directly from the data sets the original conclusions were drawn from (Nature Genet. 41, 149–155; 2009). In another study, when an identical sample of proteins was sent to different proteomics laboratories, the vast majority failed to independently, and therefore reproducibly, identify all of the component proteins (Nature Methods 6, 423–430; 2009)."